
OnnxOCR-UI简介
OnnxOCR-UI 是基于 OnnxOCR 的高级批量图片/PDF OCR 识别工具,专为高效、易用和美观的桌面批量文字识别场景设计,轻松拖入多个图片或PDF文件,即可轻松批量识别文字。
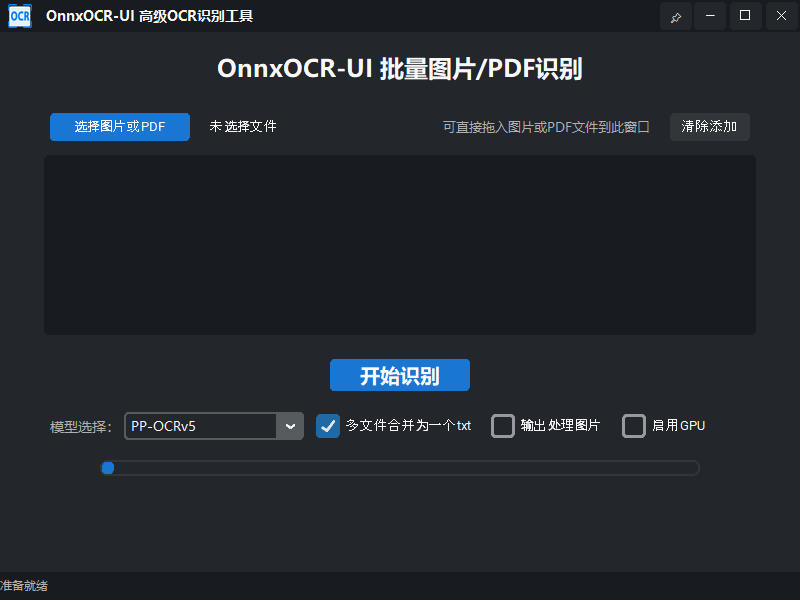
主要功能
- 支持批量图片、PDF 文件拖拽或选择添加
- PDF 转图片采用 pymupdf,无需 poppler
- 支持模型选择(PP-OCRv5、PP-OCRv4、ch_ppocr_server_v2.0)
- 进度条实时显示整体进度,PDF按页数动态更新
- 多图识别时状态栏提示平均速度
- 支持GPU加速,需英伟达显卡,电脑安装好Cuda和cuDNN
OnnxOCR简介
OnnxOCR是基于 ONNX 的高性能多语言 OCR 引擎,支持PP-OCRv54、PP-OCRv5 模型,单模型支持 5 种文字类型:简体中文、繁体中文、中文拼音、英文和日文。

- 脱离深度学习训练框架:可直接用于部署的通用 OCR。
- 跨架构支持:在算力有限、精度不变的情况下,使用 PaddleOCR 转成 ONNX 模型,重新构建的可部署在 ARM 架构和 x86 架构计算机上的 OCR 模型。
- 高性能推理:在同样性能的计算机上推理速度加速。
- 多语言支持:单模型支持 5 种文字类型:简体中文、繁体中文、中文拼音、英文和日文。
- 模型精度:与 PaddleOCR 模型保持一致。
- 国产化适配:重构代码工程架构,只需简单进行推理引擎的修改,即可适配更多国产化显卡。
PP-OCRv5 是PP-OCR新一代文字识别解决方案,该方案聚焦于多场景、多文字类型的文字识别。在文字类型方面,PP-OCRv5支持简体中文、中文拼音、繁体中文、英文、日文5大主流文字类型,在场景方面,PP-OCRv5升级了中英复杂手写体、竖排文本、生僻字等多种挑战性场景的识别能力。在内部多场景复杂评估集上,PP-OCRv5较PP-OCRv4端到端提升13个百分点。

OnnxOCR-UI安装
公众号回复“OnnxOCR-UI”,即可获取安装包。
- OnnxOCR-UI.7z为绿色版, 解压既可以使用。
- OnnxOCR-UI_v0.2.1_x64-setup.exe是安装包。
评论